Introduction
Large Language Models (LLMs) are becoming increasingly powerful, and their applications are widespread across many industries, from content creation to healthcare. Generative AI is becoming the de facto standard for multiple tasks due to its ability to generate human-like text, images, videos, and more.
For LLMs, the evergreen MLops might not be sufficient anymore. We need practices and processes designed specifically for Large Language Models. These practices and processes are called Large Language Model Operations, or LLMops for short. In this article, we will discuss what these operations are and, more importantly, how we can leverage them with AWS.
This article serves as both a high-level overview for everyone and a bit in-depth with technical details for those who want to dive deeper.
What are LLMops?
LLMops, short for Large Language Model Operations, refer to the practice of leveraging large language models (LLMs) like GPT-3, Anthropic Claude, Mistral AI, and others to automate various tasks and workflows. The core idea behind LLMops is to use the powerful generation capabilities of LLMs to create software applications, APIs, and tools that can understand and generate human-like text, images, video, and audio.
Wild! I know, right? LLMs can even generate music with soundtrack and vocals too. I wonder what they will be capable of in a few years.
The purpose of LLMops is to augment and automate a wide range of generation-related tasks that were previously labor-intensive or required significant domain expertise. So, LLMops encompass all operations needed to enable and enhance the usage of LLMs.
Key Components of LLMops
We introduced operations, let's look at what these operations actually are.
⚠️ This is a series! I'll talk in depth about each one of these practices in separate articles.
Data Preparation

In order to improve the quality of the data, there are a bunch of operations we can do:
- Text cleaning and normalization: You don't want to train your AI with your customers' credit card numbers, do you? That's essentially what you are doing here, you are cleaning the "dirt" in your data;
- Data deduplication: Removing duplicates is always a good thing, right? Your bill will thank you later on 😉;
- Data augmentation: Sometimes your data is not enough. You may need to add text classification or image description. Other times, you may need to generate generic synthetic data to include with your original data;
- Data filtering: When you don't need every piece of information in your raw data, you can filter out unnecessary data. This helps with unwanted data and unnecessary information that LLM may not need.
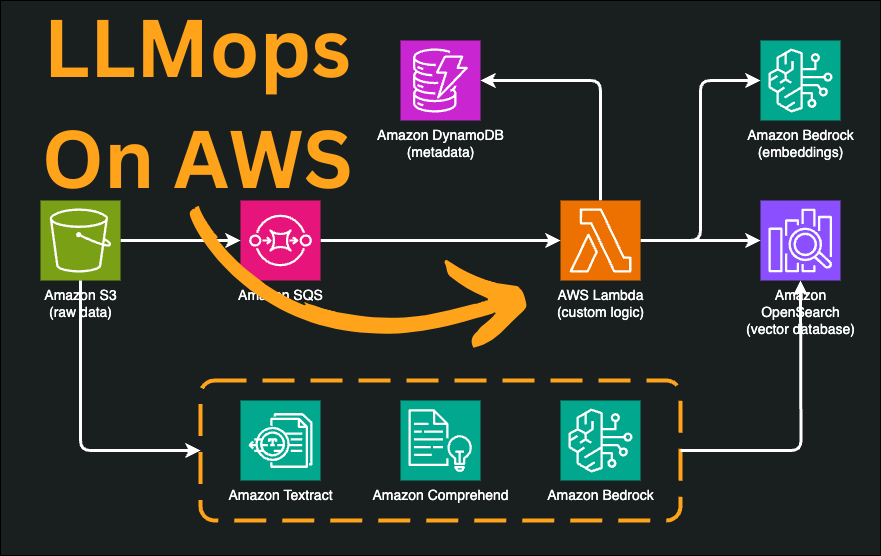
Data Ingestion

- Database: When you don't need fancy words like semantic search, a classic SQL or NoSQL database is just fine, even for AI-related tasks;
- Vector database: When you actually need fancy words like semantic search, in that case, you need to use a vector database;
- Cold storage: After the data is processed, you may want to store your raw data in some kind of cold storage to pay less and always have your data in case something happens;
- Metadata database: It's always a good thing to track metadata in a database, like file locations or simply tagging these files, for instance.
Model Evaluation
Whatever you are doing with LLMs, you must employ some kind of evaluation mechanisms in order to at least get the feeling that the LLM answers properly to your prompts.
There are soooo many ways to evaluate; the most common benchmarks are:
- GLUE (General Language Understanding Evaluation) Benchmark
- SuperGLUE Benchmark
- HellaSwag
- TruthfulQA
Not only that, of course, there are many frameworks, like Amazon Bedrock, that provide evaluation against your own prompts.
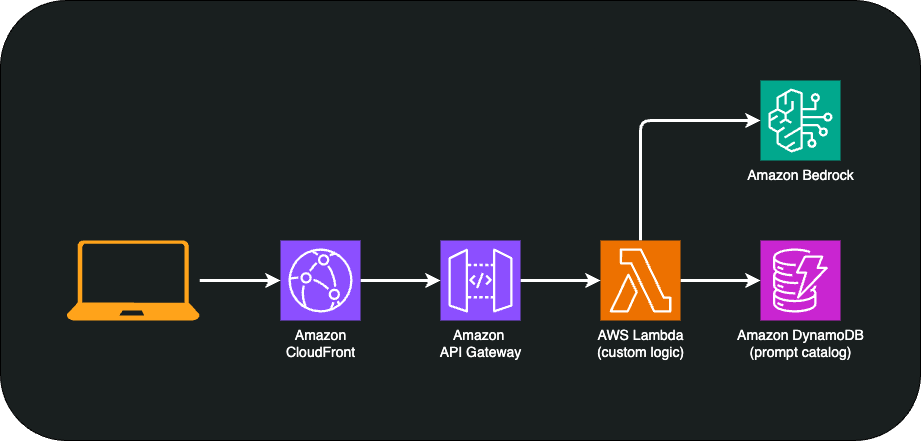
Model Deployment and Inference
Model Fine-tuning
Using the foundation model (FM) may not be enough for you; in that case, you may want to consider improving (fine-tuning) your FM with your own dataset. Consequently, you have the power of a fully working LLM with your data.
Retrieval-Augmented Generation

And this is it, with RAG we can customize our prompt with our data. One of its downsides is the limit on the context window size, which means your prompt can't be higher than a particular amount of tokens.
Model Monitoring
Monitoring is essential in every aspect of the IT sector, and in this case, it is paramount (can I say this word or only AI is allowed to?😜).
But what exactly is monitoring for Generative AI? Let's look at this list:
- System monitoring: Like every other system, you need to ensure your LLMs are up and running. So, if you deploy your LLM in your EKS cluster, then you need to ensure its scaling.
- Security: If someone is trying to hack your LLM, don't you want to know when it happens?
- Metrics to watch for: Choosing the right KPIs to monitor is essential. You may want to monitor your LLM's sentiment, its security, how many times it hallucinates, or even the quality of your LLM responses. There are so many frameworks and algorithms worth talking about when dealing with metrics to monitor, but you get the point of how this works.
Model Governance and Review
By tracking, documenting, monitoring, versioning, and controlling access to LLMs, you can control model inputs and outputs to understand what might affect LLM outputs. Major companies are struggling with keeping their LLMs unbiased, and by introducing governance and human review, you can reduce the risks of biases in your LLMs.
Granted that some models need governance more than others, but you don't want to destroy your company's reputation because your large language model said something it shouldn't have, do you? 😅
Anyway, most of the time it's not about reputation; it's about responsible AI and following its principles in order to create the safest version of your LLM.
Cost Optimization
Generative AI is expensive 💸. Usually, enterprises do not have clarity in their minds about how much it costs for them. Is it the input or output costs? What if it's the hardware, or it may be the monthly commitment? Clearly, you need a written strategy so when dealing with costs, everyone can speak the same language.
Apart from that, there are many strategies to mitigate costs in your LLMs, to mention a few of them:
- Prompt compression
- Caching
- Use RAG instead of fine-tuning
- Deploy your own model instead of using a third-party one
Prompt Engineering and Management
- Different prompt techniques
- Prompt security defenses
- Prompt versioning and tracking
- Prompt optimization and tuning
Security and Compliance
I don't need to say that Generative AI security should be the backbone of your Generative AI application design, right? We should always design solutions with security in mind.
... a few minutes after I spared you a long version of my pep talk 😜
Securing your large language model means protecting it from prompt injection, prompt leaks, DDoS attacks on your infrastructure, or even restricting the types of content it should receive/answer to.
There are many tools you can employ to get the job done. For instance, in your application, you can use guardrails to restrict input and output so your LLM doesn't answer with biased or hallucinatory text.
Model Lifecycle Management
LLMs have lifecycle management too, from model versioning to rolling back updates, or even archiving and retiring old versions of your LLM. In short, lifecycle management is essential and it includes almost all of the previous points.
LLMops on AWS
AWS is a leading public cloud provider and, as you can imagine, it offers every tool available to develop and build LLMops in the cloud. Throughout this article, you probably saw some reference architecture of how we can build that particular solution using AWS services.
At its core, Amazon Bedrock is a fully managed service that provides access to foundation models (FMs) created by Amazon and third-party model providers through an API. Additionally, we can fine-tune it, run AI Agents, have its knowledge base, and even add guardrails and review your own LLM.
Amazon Bedrock, along with a couple of other serverless services, can get us through each and every aspect of LLMops.
⚠️ To know more about it, you can check out my blog post regarding Amazon Bedrock: 🔗 The Complete Guide to Amazon Bedrock for Generative AI
Conclusion
And "that" is it, folks. Hopefully, I was able to make a good recap of what LLMops are and how we can do it on AWS. You probably noticed I didn't go into details regarding infrastructure, procedures, etc., why is that? Because I wanted to write about them in detail in my upcoming articles 😉
Future articles will be listed somewhere "here" and they will talk about each LLM operation in depth, with reference architecture and projects to follow along.
If you enjoyed this article, please let me know in the comment section or send me a DM. I'm always happy to chat! ✌️
Thank you so much for reading! 🙏 Keep an eye out for more AWS related posts, and feel free to connect with me on LinkedIn 👉 https://www.linkedin.com/in/matteo-depascale/.
Disclaimer: opinions expressed are solely my own and do not express the views or opinions of my employer.