
Thanks to @robertdmanus on Pinterest for the cover image
Introduction
Every great journey starts with a struggle. And for me, that struggle began as I built my own blog and struggled to find the right caching strategy. I knew that in order to succeed, I had to go above and beyond, carefully studying every solution that would optimize my website's performance. But even after going through documentations, articles and tutorials, I still had that feeling that it wasn't enough. That I was missing out on some opportunities. So, I took my notebook and pen, and I started experimenting with all the possible settings, determined to find the perfect caching strategy for my website. In this article, I'll share my knowledge about caching, explore some of the most effective caching pattern, and take you on a deep dive into my personal experience with finding the right caching strategy for my own website. Let's start this exciting journey!🚀
The 6W of caching
What is the cache?
Caching is the process of storing frequently accessed data or resources in a temporary location that's placed in between you browser and your server.
Why is the cache important?
It can improve website speed as well as performance, which can lead to a better user experience. Not only that, but caching is amazing because it reduce server load and network usage, which can lower costs.
Where should you use the cache?
You can cache a lot of website resources, including HTML pages, images, stylesheets, scripts and Api. Also, you can use the cache at different levels, such as server-side, client-side, database and even DNS.
When should you use the cache?
Definitely when you want to improve website speed and performance, as well as reducing server load and network costs. It's more effective for frequently accessed data or static resources.
Who should use the cache?
You! Yeah this was lame😜. Anyway, anyone who owns a website should use the cache to improve their website performance, particularly if they have high traffic.
How to cache effectively?
No wonder why I put this question last. To cache effectively, you should consider caching patterns and cache-control header that are most suitable for your website. Yeah, it's another "it depends", but it was more structured this time, and I will provide all the info in the following sections.
How does caching a web application work?
To better understand the concept of caching, let's draw some diagrams👇. The actions are made following this sequence:
- The client asks the cache for the list of posts from the Api;
- The cache searches internally, but it doesn't find anything;
- The cache asks the Api the list of posts;
- The Api returns the list of posts;
- The cache saves the list locally and returns it to the client.
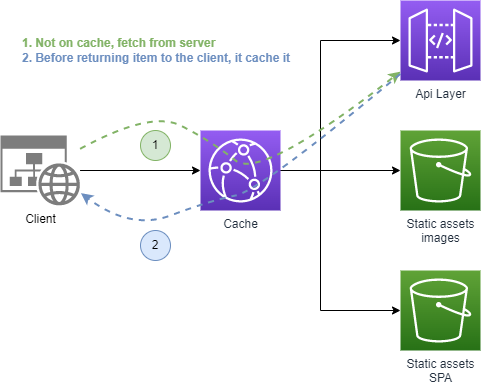
As of now, the client has received the list of posts, and the cache has store it locally. What happens when the client makes the same request again?
- The client asks the cache for the list of posts from the Api;
- The cache searches internally, it does find it;
- The cache returns it to the client.

The cool thing about all of this is that your cache is faster than the entire roundtrip to your Api, which means users are able to see content sooner, resulting in a better user experience. Additionally, your Api will thank you 🙏.
There is also another case of caching which is really important, and most of the times, it's the cause of misalignments between the new version and the old one. The browser can cache too, in order to make the website load as fast as possible 💨.

Now that we know all the possible ways to cache with a website, how does your browser or the cache know when it's time to refresh the item?
To answer this question, we need to talk in-depth about the Cache-Control header!
Content Delivery Network (CDN) is group of servers, distributed across the globe, that caches content near end users. It's one type of caching mechanism, it's really effective for static content, so if we are using S3 we are going to serve S3 static files though Amazon CloudFront which is Amazon CDN. https://aws.amazon.com/cloudfront/
Cache-Control header
With Cache-Control, we are able to control caching on our website. This header instruct users' browsers how to cache resources like images, CSS, scripts, etc.
There are a lot of directives. I'll cover some of the main ones, but if you want to check all of them out, I encourage you to take a look here https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control.
Let's go though some of the main directives for cache control:
- public: the resource can be cached by any cache such as browser or CDN;
- private: the resource can be cached only by users' browsers. Could be useful when serving personalized content to users, and you don't want others to access them;
- no-cache: browsers must revalidate the cached resource before serving it to users;
- no-store: browsers must not store the resources at all;
- max-age: the resource maximum amount of seconds that can be cached before fetching it again;
- must-revalidate: tells the browser that it always needs to validate the cache with the CDN before using it;
- immutable: the resource won't change while it's cached. This is very effective for item that do not change, like images.
By using these directive in the Cache-Control header, you can control how website resources are cached. Let's look at a few examples:
- Cache-Control: no-cache, no-store, max-age=0, must-revalidate. This one is not really tricky, is it? You want to be double sure that users always see the latest version of the resource;
- Cache-Control: public, max-age=86400, immutable. This directive tells browsers and CDN will cache the object for 1 day. After that, the resource will be fetched from the CDN.
You may have noticed me mentioning CDN and S3. Let's explore how those guys can work together towards a common goal: improving website performance!
Amazon CloudFront with Amazon S3
CloudFront is a powerful CDN that can improve website speed and performance by caching resources on edge location, which are closer to the user. To control caching behaviors on CloudFront, you can specify a cache policy. A cache policy defines how CloudFront should cache resources, like its headers, query strings, paths, etc. Cache policy comes in two flavors:
- Managed: Amazon-managed cache policies, which are suitable for most use cases;
- Custom: personalized cache policies, which, for example, allow you to cache an item for a specific amount of time.
In addition to setting cache policies on CloudFront, you can also specify the cache-control header on your origin (S3) files. What happen when you combine CloudFront cache settings with the cache-control header?
When CloudFront fetches a resource for S3, it checks the cache-control header to determine how long it should cache the resource. This part is a little tricky because CloudFront can override the origin file cache-control header and use its own policy. This is actually great because it allows us to customize the caching policy for our CDN and users' browsers.
Here are a few examples of how CloudFront and S3 can work together:
- If CloudFront has a minimum TTL of 60 seconds and a resource has a Cache-Control header with max-age=30, CloudFront will cache the item for 60 seconds while the browser will cache it for 30 seconds;
- If CloudFront has a minimum TTL of 60 seconds and a maximum TTL of 180 seconds and a resource has a Cache-Control header with max-age=120, both CloudFront and the user's browser will cache the item for 120 seconds;
- If a resource's cache-control header cannot be changed, and browsers are receiving items without a cache-control header, they will make requests to CloudFront every time. In this case, we can override the Cache-Control header of our objects by creating a custom "response headers policy" (as well as removing headers). After the association with our origin, browsers will see the Cache-Control header;
- If CloudFront has a minimum TTL of 10 hours (36000 seconds), and a resource has a Cache-Control header with max-age=7200 (2 hours), browsers will cache the item for 2 hours. If you decide to invalidate the CloudFront cache after 1 hour, browsers will still have the old item for at most another hour before making a new request to CloudFront.
If you want more examples of how CloudFront behaves with Cache-Control header coming from the origin, I suggest taking a took at this resource: https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/Expiration.html
Cache invalidation: keeping your CDN up-to-date

As developers, we all want to ensure that our users are seeing the latest version of our applications. That's when cache invalidation comes in. I personally love using this technique with CloudFront and I think it's a must-do step when deploying a new version of our web application. Let's take a closer look at how it works with some real use cases.
Case 1: Deploying SPA to S3
When you deploy your single-page application (SPA) to S3, you need to create a new invalidation to tell CloudFront to remove currently cached resources. By doing this, when users ask for resources, CloudFront fetches the latest version from S3.
Case 2: Updating Images
Let's say you have a new version of an image that you want CloudFront to serve. You can create a new invalidation of that specific image, specifying the path of the resource that needs to be invalidated. By doing this, CloudFront will remove only that specific object from the cache, while every other object remains cached.
Finally we are getting somewhere, but I'm afraid it's still not enough. The invalidation doesn't prevent browsers from caching but it ensures that, when browsers ask the CDN for a resource, it does return the latest version of that resource.
To solve this big puzzle we just have to answer one more stinging question: How can we force browsers to always download the latest resource?
Forcing browsers to get the latest version
Luckily there are several ways of forcing our browser, some techniques are:
- Cache-Control: we can use this header to ensure browsers don't cache the item. To do so we can set the header to "no-cache" or "max-age=0". Unfortunately this means that browsers won't cache a bit of our resources;
- Cache bursting: is a common technique that add an uniquely identifier to the resources, in my opinion there are two ways of doing it:
- editing the file url in order to add an unique identifier of that resources. For example, you can add ?version=20230328 as query string or /v2/ as path parameter;
- editing the file name in order to create a complete new item. For example, you can add files with names that include a unique identifier, such as style_uuid123.css. This strategy ensure the browser always request the last item.
Most framework like Angular, React and Svelte already use techniques to trick browsers into getting the latest file version. I'm using SvelteKit right now, and when I build my SPA I get these files:

You probably already spotted them, there are files containing an unique identifies in their name and some of them who don't. Some of them can be cached indefinitely, like favicon.ico. On the contrary, index.html, is a little bit special and requires a special treatment⭐️.
To understand why index.html is special we need to take a look at its code:
... <link rel="modulepreload" href="/_app/immutable/entry/start.7802d367.js"> <link rel="modulepreload" href="/_app/immutable/chunks/index.af49b43e.js"> <link rel="modulepreload" href="/_app/immutable/chunks/singletons.56ce5c0b.js"> <link rel="modulepreload" href="/_app/immutable/chunks/index.323fade2.js"> <link rel="modulepreload" href="/_app/immutable/chunks/control.e7f5239e.js"> <link rel="modulepreload" href="/_app/immutable/entry/app.8ea2a269.js"> <link rel="modulepreload" href="/_app/immutable/chunks/preload-helper.41c905a7.js"> ...