
Introduction
So... I know you've heard about Generative AI, LLMs, and all of that, BUT this article won't focus entirely on those topics. Instead, we are going to learn how to leverage AWS services and/or open-source tools to prepare our data for optimal LLM usage.
In this blog post, we will go through a bit of theory about data preparation and discuss the tools and services we can use to optimize data preparation on AWS for language models.
Before we start, this is the second part of a series on LLMOps on AWS. Reading the first part is not required if you are interested in just "Data Preparation on AWS." If you want to read about "LLMOps on AWS," here's the link: 🔗 https://cloudnature.net/blog/large-language-model-operations-llmops-on-aws

What Is Data Preparation?

Why do we need data preparation? Actually, we can answer this question with another question (I know, lame?! 😜). What's the first thing that comes to mind when someone says, "as soon as we gather the data, our LLM starts the training process without checking the quality or validity"? Well... I bet you thought something like: "this is a recipe for disaster."
And I quite agree with this statement, but don't take my word for it, take it from Dr. Werner Vogels instead:

"Good data, good AI," he said during his re:Invent keynote. This underscores the importance of "Data Preparation," transforming our bad data into good data.
Did you know that 60% of a Data Scientist's time is spent preparing data? Source.
Data preparation involves several steps:
Extracting: This step involves fetching and storing raw data from various sources into a centralized system. It ensures that all necessary data is available for subsequent processes. Sources can include databases, APIs, files, or streaming data.
Cleaning: This is the process of removing unwanted elements from the data. This includes eliminating personally identifiable information (PII), correcting errors, removing duplicates, and dealing with missing values. The goal is to enhance the quality and reliability of the data.
Augmenting: This involves adding additional information to the dataset to enhance its value. This can include integrating data from external sources, deriving new features from existing data, or applying domain-specific knowledge to improve the dataset's comprehensiveness and relevance.
Now that we understand what data preparation is, let's look at the tools available on AWS to improve data handling for AI.
⚠️ Note: we are not going to talk about "Chunking" as the topic is quite big and I'd like to cover it in another blog post.
AWS Services for Data Preparation

Data preparation involves multiple stages, each requiring specific tools to ensure the data is accurate, reliable, and ready for analysis. AWS offers a wide range of services to support these steps, making the data preparation process efficient and scalable.
Below are the key stages of data preparation and the AWS managed services that can assist in each step:
Extracting
- AWS Glue
- Amazon S3
- AWS Lambda
- Amazon Textract
- Amazon Bedrock
Cleaning
- AWS Glue
- Amazon EMR
- AWS Lambda
- Amazon Bedrock
Augmenting
- Amazon Comprehend
- AWS Lambda
- Amazon Bedrock
As you can see, there is a mix of services, and you can notice Amazon Bedrock appears in all three steps. Why? Because with Large Language Models (LLMs), you can use their vision capabilities to extract, their text capabilities to clean the text, and then, of course, augment the text with more content or a recap of that content. Just keep in mind, Generative AI is not cheap! Most of the time, you're better off using managed services or creating a solution yourself.
For managed services, we have many options in AWS, such as Glue, Comprehend, and Textract. Using them together will create your AI workflows on AWS. We will see an example later on ✌️
Anyway, a few lines above, I mentioned something like: "Just do it yourself, mate!". Did you know that you can use open-source libraries directly in your Lambda function? Yep, let's look at a few tools we can use for data optimization 💪
Open Source Tools (That Could Do the Job Just Fine)

There are many out there; we can work with complete tools, like Apache NiFi for extracting or OpenRefine for cleaning. Or we can do it ourselves using some compute power (like our trustworthy AWS Lambda functions) and open-source libraries.
They might not be as accurate as managed services, but I'm sure some projects can benefit highly from these libraries. Let's look at a few of them:
Extracting
- PyPDF2 / PyMuPDF: Python libraries for extracting text from PDF files.
- CSVLoader (from LangChain): Python library for reading CSV files.
- UnstructuredMarkdownLoader (from LangChain): Python library for reading Markdown files.
Cleaning
- Pandas: A flexible and powerful data manipulation library for cleaning and processing data.
- Dedupe: A Python library for de-duplication and entity resolution.
- DataCleaner: An open-source toolkit for data cleaning, handling missing values, and correcting errors.
Augmenting
- SpaCy: An NLP library for text processing, which can be used to augment datasets with linguistic features.
- PyTorch Transforms or MXNet Transforms: Python libraries for computer vision tasks.
These are just a few of the libraries available; I didn't want to write the article without mentioning them! Also, some of these libraries can run on a serverless AWS Lambda function, while others may need more computing power or long-running processes. In that case, there are many available options, such as spinning up an EC2 Spot Instance to run these jobs.
Alright! We have our basic know-how of how things could work in the "Data Science" world. It's time to see some data preparation techniques with AWS managed services 👇
Data Preparation
To better understand how data preparation works on AWS, I've created a small project using various managed AWS services to illustrate how they all fit together to create best practices for LLMOps.
The project I built focuses on enhancing company privacy, as data privacy has become a top priority for companies across all sectors. This is not only for compliance with regulations like GDPR but also for maintaining customer trust.
Let's imagine a large financial company called AsyncAssets Finance that manages a vast number of documents, including contracts, financial reports, and correspondence with clients. These documents often contain sensitive information such as account numbers, email addresses, and phone numbers. The challenge is to automate the removal of personally identifiable information (PII) to protect sensitive data without compromising the integrity of the documents.
Let's look at the data preparation techniques for this use case 👀
Storage Strategy
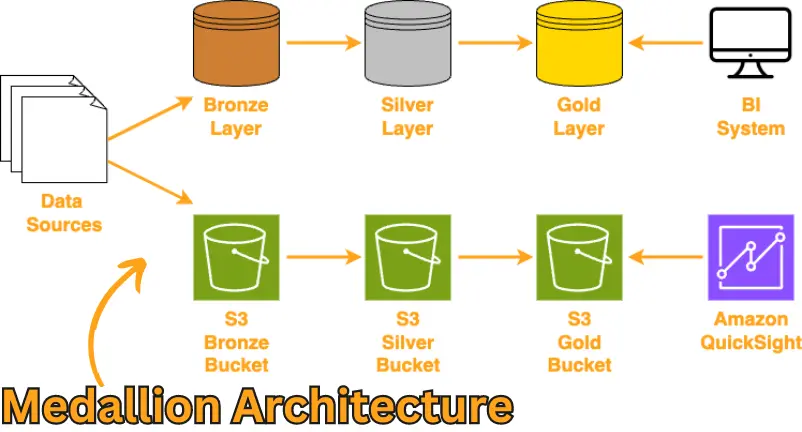
Before we move into the coding part, I want to highlight the storage strategy to guarantee the best language model performance on AWS.
We are going to follow the "Medallion Architecture":
- The "bronze" S3 bucket contains raw data.
- The "silver" S3 bucket contains extracted and formatted data.
- The "gold" S3 bucket contains data ready to be used by applications/BI tools.
Ideally, the data should move from "bronze" to "gold" in our data preparation workflow on AWS.
Extracting
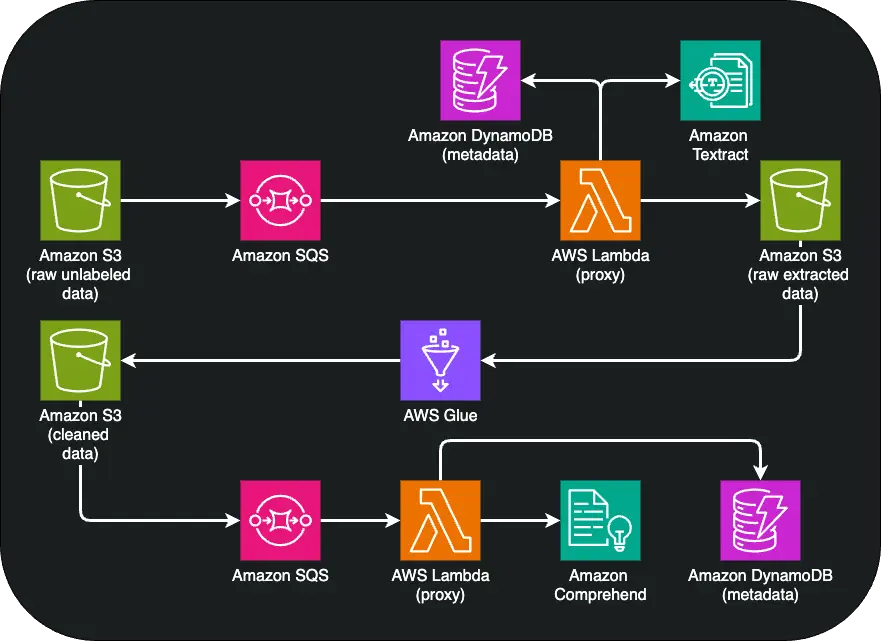
The first step in our LLMOps pipeline involves extracting data from PDFs using Amazon Textract, a machine learning tool capable of reading and understanding text in documents, even those with complex formatting.
We use an event-driven approach: when raw data is uploaded to the "bronze" bucket, an AWS Lambda function is triggered. This Lambda function initiates the Amazon Textract process to extract text and metadata from the document. Since this process is asynchronous, we specify an Amazon SNS topic to receive alerts when the extraction is complete. The output is then stored in our "silver" S3 bucket.
Once the Amazon Textract job finishes, our Amazon SNS topic receives a notification. We store the metadata in Amazon DynamoDB and the document text in the "silver" S3 bucket.
Now, let's jump to the next part of optimizing data on AWS 👇
Cleaning

The next step in our LLMOps journey involves cleaning the extracted data by removing any Personally Identifiable Information (PII). Here, AWS Glue is utilized to identify and redact PII, such as email addresses and phone numbers, by configuring it to search for specific patterns.
Similar to the previous step, when the extracted text is saved in our "silver" S3 bucket, a new AWS Lambda function is triggered. This Lambda function initiates the AWS Glue PII redaction job via API. The job, essentially a PySpark script using Glue's libraries, detects and redacts PII. Finally, the script updates the result in our "gold" S3 bucket.
Pro Tip: The visual editor in AWS Glue is phenomenal. You can accomplish almost anything without writing code. Once the boilerplate setup is done, you can add your own custom logic.
Augmenting
After removing PII, we use Amazon Comprehend to classify the remaining data and understand its context, categorizing documents appropriately. This step helps in organizing data and identifying the type of information each document contains. Since AsyncAssets Finance operates internationally, we need a way to identify the language of documents for metadata enrichment and labeling purposes.
Our data preparation pipeline on AWS wouldn't be complete without enriching our data, such as determining the document language. When the redacted text reaches the "gold" S3 bucket, another Lambda function processes this text using Amazon Comprehend to detect the document language.
Detecting the document language is a straightforward synchronous process that can be done with a Lambda function. If the result meets our accuracy threshold (at least 90%), we store the detected language in our metadata NoSQL database.
Results
At the end of our data preparation pipeline on AWS, we have a comprehensive metadata database and processed text files ready for querying.
The accuracy of PII removal and language detection is impressive. However, the results of PDF extraction heavily depend on the original format. For instance, documents with tables may result in extracted text that is not always easy to understand.
Nevertheless, while this project is simple, it holds potential for addressing numerous use cases and can be further improved 💪
Conclusion
And with that, our journey through LLMOps, specifically focusing on data preparation on AWS, comes to a close. I hope this has been informative and has sparked ideas for your future projects (or backlog 😜).
As for the code, it's all written in Terraform and you can deploy it in your own environment by following the README!
See you in the next article discussing LLMOps and best practices 👋.
You can find the repository here: https://github.com/Depaa/llmops-data-preparation-on-aws 😉.
If you enjoyed this article, please let me know in the comment section or send me a DM. I'm always happy to chat! ✌️
Thank you so much for reading! 🙏 Keep an eye out for more AWS related posts, and feel free to connect with me on LinkedIn 👉 https://www.linkedin.com/in/matteo-depascale/.
Disclaimer: opinions expressed are solely my own and do not express the views or opinions of my employer.